

前言
ES作为搜索领域一款举足轻重的开源搜索引擎,对它的研究和学习对我们提升搜索相关知识技能,对后端理解搜索技术架构都有非常大的帮助,这里笔者总结了对ElasticSearch相关调研和开发经验,将其整理为《Elasticsearch高手之路》系列,本章着重讲解ES的基础和查询语法。
ES简介
背景介绍
elasticsearch 不仅是一款开源软件,其背后是一家上市公司


在db-engines给出的评分中,ES名列前茅
https://db-engines.com/en/ranking/search+engine
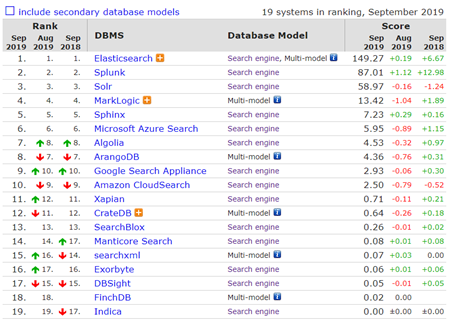
es经历了一系列版本升级后,目前的最新版本为7.0 (2019-09)

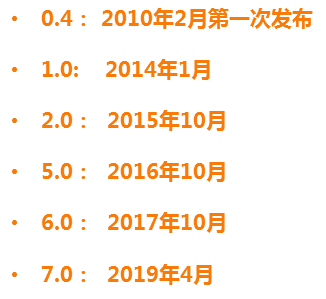
Elastic Stack 生态圈
Kibana ——可视化分析 2013年被es收购
借助它我们可以实现多维度服务器监控、日志查看甚至基于机器学习的报警规则
更方便的是,由于自带查询语法提示,我们通过其查询工具可以快速完成es查询语法书写
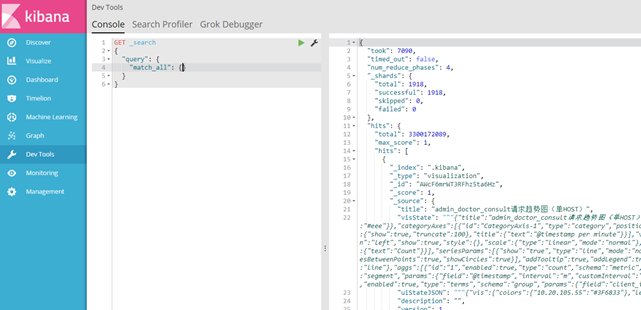
ES管理工具——cerebro 优秀的轻量化的Es集群管理工具
1、索引管理
2、节点状态监控
3、查询编辑器
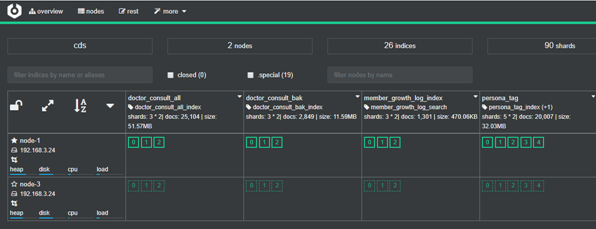
ES索引结构
mapping文件
在solr中,我们需要这两个文件创建一个索引
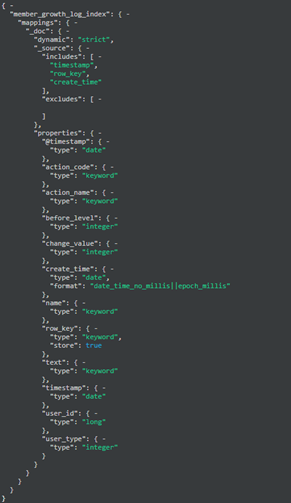
在ES里,我们称之为mapping
创建索引的API为
PUT /create_index/create
mapping内定义了
1、settings
节点配置信息,包括分片数,字段类型等
2、mapings
字段映射信息,字段名称、类型和相应配置
支持的字段类型
主要类型7类 19个
其他类型18类
https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-types.html
例如: IP

Text: 主要用于需要进行分词的字符串信息
Keyword:类似于solr 的string
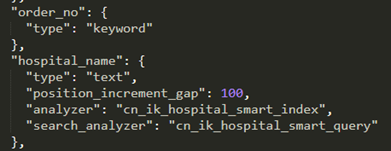
solr内的多值字段,在es里叫数组,并且任何类型都可以是数组(比solr方便多了有木有~)

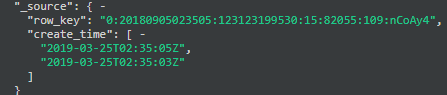
Range field:
这个字段类型比较特殊,solr里没有,是通过一个上下限表示的字段范围
比如我定义如下一个字段


然后查12
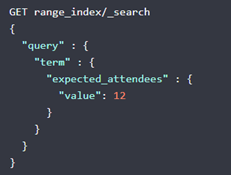
就可以查到它

Object类型——支持更灵活的字段创建
例如:
我们将hive内存储的几十张表数据和字段存储于一个index内
取用的时候就是 ${index}.${table}.${field}
自动索引字段映射允许我们提交一个拥有嵌套结构的文档,
嵌套Mapping便自动生成

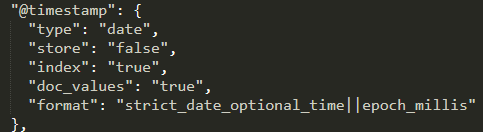
字段附属配置信息
与solr类似,一个字段也有store index这些配置,当然es的字段也有一些特殊配置
ES
solr

比如keyword的一些配置说明
https://www.elastic.co/guide/en/elasticsearch/reference/current/keyword.html
嵌套字段:fields ————————字段的字段
例如:client_type 进行分词,而client_type.keyword 不分词
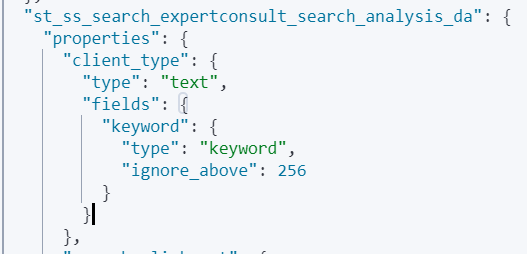
分词类型配置
我们可以配置自定义分词类型和字典等,这块参考es ik、hanlp分词配置即可,官网和各大微博都有
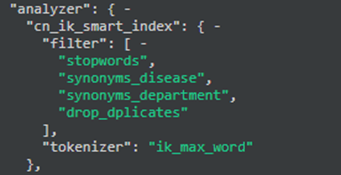
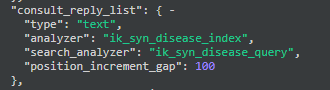
IK词库配置
主要就是这个文件了 IKAnalyzer.cfg.xml
这里配置主要是扩展词典和远程词库

验证词库配置
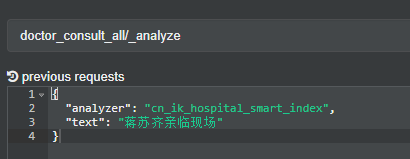
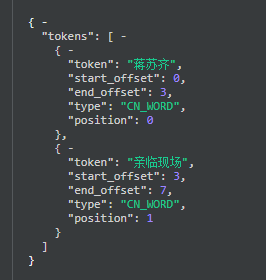
索引一份文档
1、PUT ${index_name}/_doc/${id}
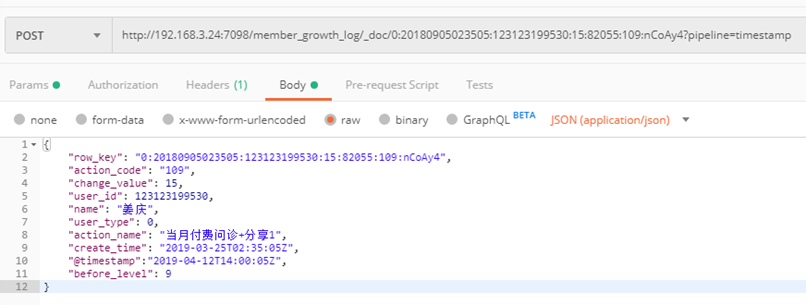
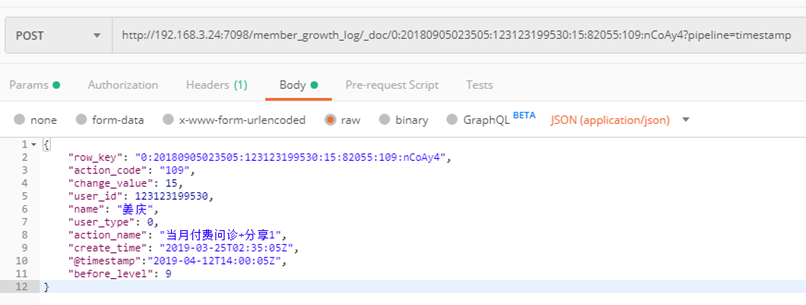
2、PUT ${index_name}/_doc/${id}?pipeline=${pipelinename} 自动添加时间戳
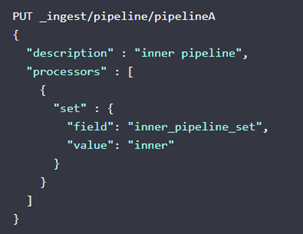
Pipeline流水线
pipeline定义了索引文档前的一些动作
API为
/_ingest/pipeline/xxx
这个定义了自动添加一个字段,值为inner
下面这个就是定义了自动添加时间戳的pipeline
{
"description" : "timestamp",
"processors" : [
{
"date" : {
"field" : "_ingest.timestamp",
"target_field" : "@timestamp",
"formats" : ["yyyy-MM-dd'T'HH:mm:ss.SSSZZ","yyyy-MM-dd'T'HH:mm:ssZZ","yyyy-MM-dd HH:mm:ss","epoch_millis","UNIX"],
"timezone" : "UTC"
}
}
]
}批量索引文档
1、PUT /_bulk
第一行定义行为,第二行就是具体文档键值对

Es常用DSL查询
DSL————Domain Specific Language:领域特定语言
Es起源于json 和Restful API流行时期
Elasticsearch基于JSON提供完整的查询DSL来定义查询
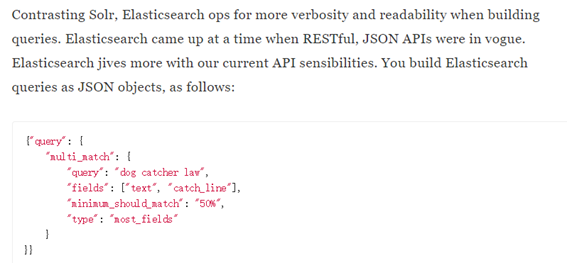
最简单的查询
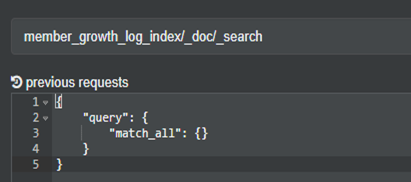
查全部文档
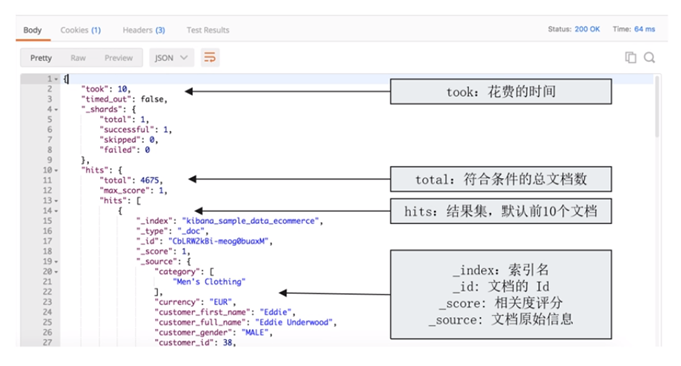
返回结果说明
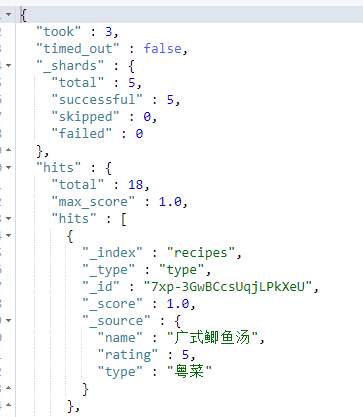
这里我们定义一个菜谱结构文档,用以说明各种查询语法
结构如下,就三个字段 菜名、类别、受欢迎程度 1-5
针对一个字段的查询
最简单的term查询

返回结果
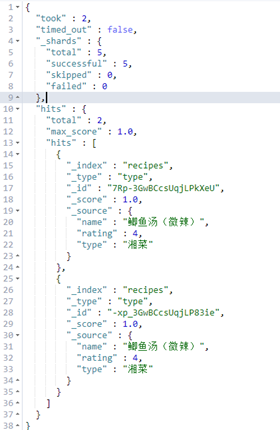
那么问题来了,为啥要用上面这种结构查询呢?
查询结构
Leaf query clauses 叶子查询字句:Leaf query clauses 在指定的字段上查询指定的值, 如:match, term or range queries. 叶子字句可以单独使用.
Compound query clauses 复合查询字句:以逻辑方式组合多个叶子、复合查询为一个查询

通过复合查询,我们将不同的叶子查询进行组合,进一步构造更复杂的查询,下面我们来开一下查询分类.
查询分类
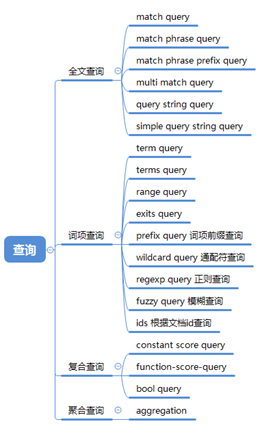
简单查询
Query context 查询上下文:用在查询上下文中的字句回答“这个文档有多匹配这个查询?”。除了决定文档是否匹配,字句匹配的文档还会计算一个字句评分,来评定文档有多匹配,会参与相关性评分。查询上下文由 query 元素表示。
Filter context 过滤上下文:过滤上下文由 filter 元素或 bool 中的 must not 表示。用在过滤上下文中的字句回答“这个文档是否匹配这个查询?”,不参与相关性评分。被频繁使用的过滤器将被ES自动缓存,来提高查询性能。

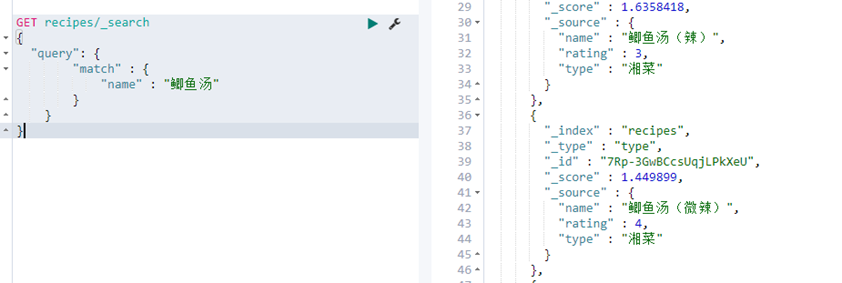
全文查询——match query
全文查询的标准查询,它可以对一个字段进行模糊、短语查询
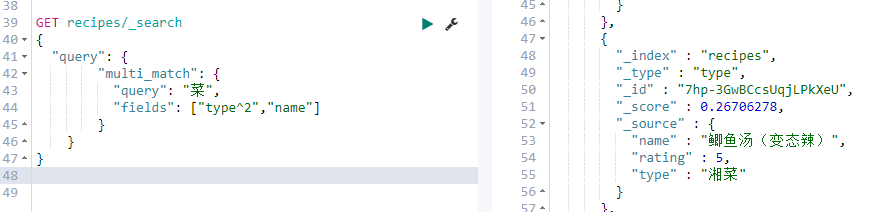
全文查询——multi match query
与match query类似,针对多个字段,类似solr q和qf
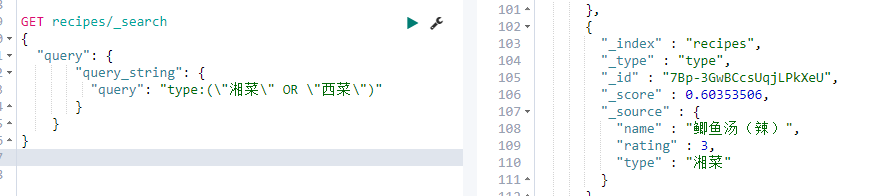
全文查询——query string query
让我们可以直接用lucene查询语法写一个查询串进行查询
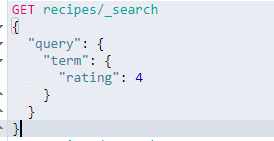
词项查询——term query
term 查询用于查询指定字段包含某个词项的文档

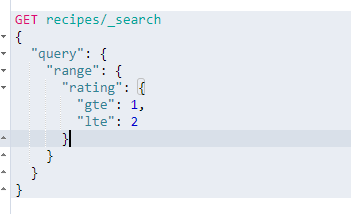
词项查询——range query
范围查询用于查询指定字段在某个范围的文档
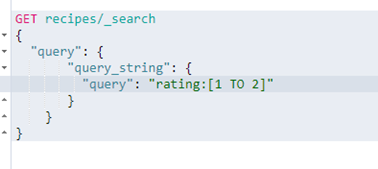
当然也可以直接用string query

复合查询——bool query
举个例子:类型是湘菜,不喜欢奶油鲍鱼汤,评价在4~5范围内


复合查询——function_score_query
在讲这个之前先提一下这个语言
Painless语言——————这个脚本语言和javascript很像,从名字也可以看出它的目标就是降低学习成本,让你上手就可以做事情。
官方介绍是这样的

帮大家翻译一下

比如我现在需要按照某个特定规则进行排序,计算公式是 Score=5/(1.2)^rating
查询是这样的
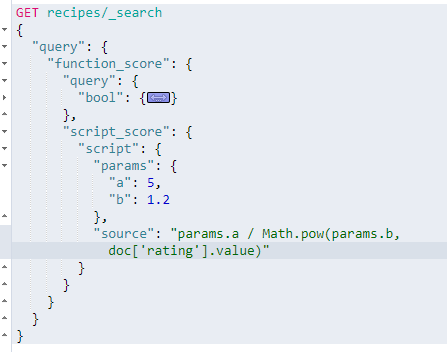
聚合查询——agg_query
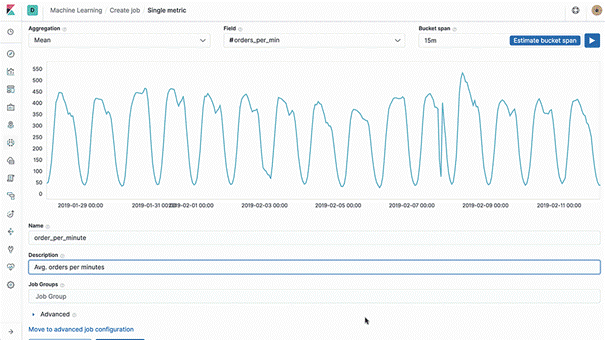
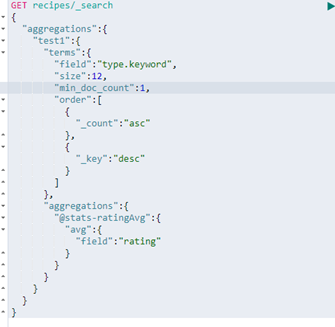
在kibana统计中使用的查询
这里聚合一下每种类型的菜有多少,然后每个类型计算一下平均评分
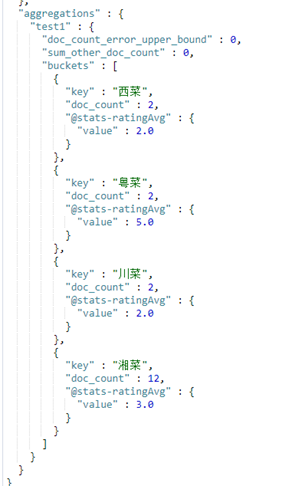
看完以上介绍,有没有对ES语法有了一丝了解?如果还是比较懵逼,还有办法
Search-core的solr语法解析器
微医搜索团队自主研发了solr语法转换器,通用查询语法转换器,用以将solr语法转换为等价es查询,便于solr搜索开发人员无缝衔接es相关开发工作
目前能够做到将搜索云平台90%的参数转换为es查询语法
例如solr里的分组,可以等价转换为es内的collapse
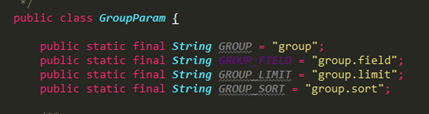
编写具体参数
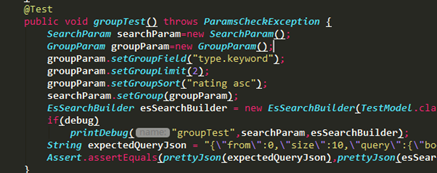
转换结果
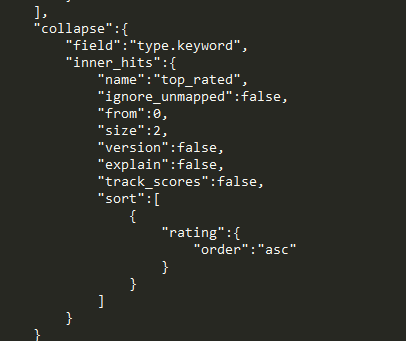
Es原生sql的支持
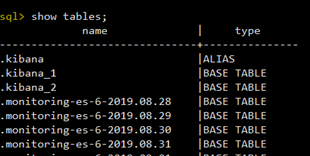
1、命令行方式
./elasticsearch-sql-cli 127.0.0.1:9200
直接使用es自带工具,在bin下面
进入命令行
2、api方式
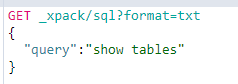
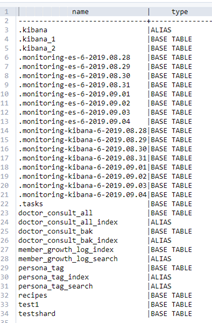
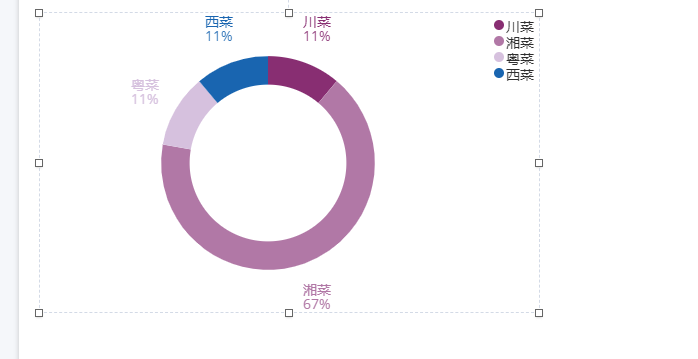
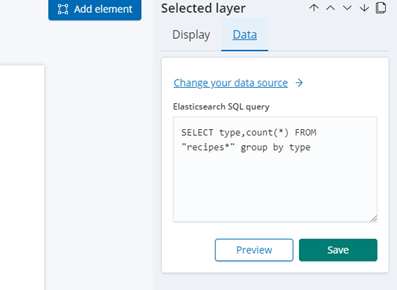
通过sql我们也可以生成一些报表
使用kibana的canvas
ES相关技术栈
这里给出eBay Pronto 平台技术负责人--阮一鸣整理的一份es相关技术栈,开发们共勉
未完待续...