

前言
ES作为搜索领域一款举足轻重的开源搜索引擎,对它的研究和学习对我们提升搜索相关知识技能,对后端理解搜索技术架构都有非常大的帮助,这里笔者总结了对ElasticSearch相关调研和开发经验,将其整理为《Elasticsearch高手之路》系列,本章着重讲解ES的性能优化。
我们要知道如何优化性能, 就要了解ES或者solr是如何利用资源的
索引原理
Lucene操作document的流程
Lucene将index数据分为segment(段)进行存储和管理.
Lucene中, 倒排索引一旦被创建就不可改变, 要添加或修改文档, 就需要重建整个倒排索引, 这就对一个index所能包含的数据量, 或index可以被更新的频率造成了很大的限制.
为了在保留不变性的前提下实现倒排索引的更新, Lucene引入了一个新思路: 使用更多的索引, 也就是通过增加新的补充索引来反映最新的修改, 而不是直接重写整个倒排索引.
—— 这样就能确保, 从最早的版本开始, 每一个倒排索引都会被查询到, 查询完之后再对结果进行合并.

文档索引流程
① 将数据写入buffer(内存缓冲区);
② 执行commit操作: buffer空间被占满, 其中的数据将作为新的 index segment 被commit到文件系统的cache(缓存)中;
③ cache中的index segment通过fsync强制flush到系统的磁盘上;
④ 写入磁盘的所有segment将被记录到commit point(提交点)中, 并写入磁盘;
④ 新的index segment被打开, 以备外部检索使用;
⑤ 清空当前buffer缓冲区, 等待接收新的文档.
(a) fsync是一个Unix系统调用函数, 用来将内存缓冲区buffer中的数据存储到文件系统. 这里作了优化, 是指将文件缓存cache中的所有segment刷新到磁盘的操作.
(b) 每个Shard都有一个提交点(commit point), 其中保存了当前Shard成功写入磁盘的所有segment.
系统cache对搜索的影响
我们在solr内看到的内存占用总是打满, 就是linuxcache在偷偷使用内存, 正是他的存在, 将搜索速度提升了一个量级
关于linux cache扩展阅读 https://www.ibm.com/developerworks/cn/linux/l-cache/index.html
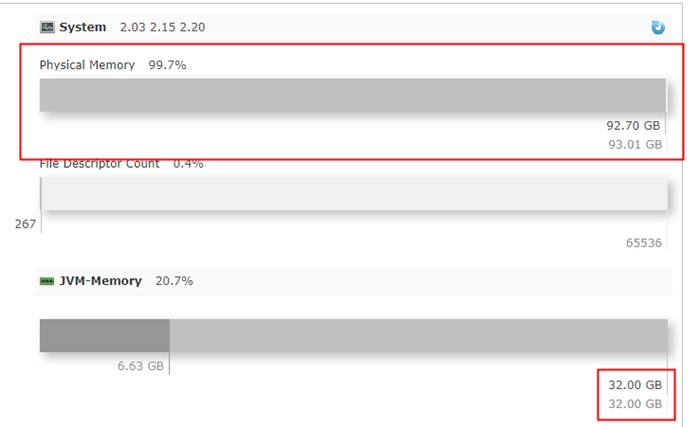
从jmeter的测试结果我们可以明显看出来 刚开始的qps只有几百 渐渐提升到几千
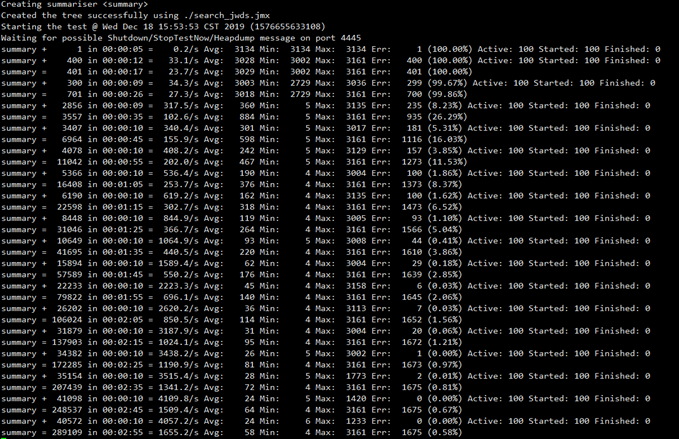
从服务器的监控也可以看出, 此时磁盘io严重, 正在进行频繁的读取索引文件到内存, 生成cache, 此过程一旦完成,搜索速度将得到质的提升
文档删除流程
① 提交删除操作, 先查询要删除的文档所属的segment;
② commit point中包含一个.del文件, 记录哪些segment中的哪些document被标记为deleted了;
③ 当.del文件中存储的文档足够多时, ES将执行物理删除操作, 彻底清除这些文档.
在删除过程中进行搜索操作:
依次查询所有的segment, 取得结果后, 再根据.del文件, 过滤掉标记为deleted的文档, 然后返回搜索结果. —— 也就是被标记为delete的文档, 依然可以被查询到.
在删除过程中进行更新操作:
将旧文档标记为deleted, 然后将新的文档写入新的index segment中. 执行查询请求时, 可能会匹配到旧版本的文档, 但由于.del文件的存在, 不恰当的文档将被过滤掉.
区别于关系型数据库, 文档的删除是一个比较消耗性能的操作
近实时索引 NRT
Solr 的 soft commit / es 的refresh
(1) 现有流程的问题:
插入的新文档必须等待fsync操作将segment强制写入磁盘后, 才可以提供搜索.而 fsync操作的代价很大, 使得搜索不够实时.
(2) 改进写入流程:
① 将数据写入buffer(内存缓冲区);
② 不等buffer空间被占满, 而是每隔一定时间(es默认1s solr 是commitWithIn), 其中的数据就作为新的index segment被commit到文件系统的cache(缓存)中;
③ index segment 一旦被写入cache(缓存), 就立即打开该segment供搜索使用;
④ 清空当前buffer缓冲区, 等待接收新的文档.
—— 这里移除了fsync操作, 便于后续流程的优化.
优化的地方: 过程②和过程③:
segment进入操作系统的缓存中就可以提供搜索, 这个写入和打开新segment的轻量过程被称为refresh.
但是这个时候,数据都在内存里, 如何避免断电数据丢失呢? 于是有了tlog
Elasticsearch/Solr 通过事务日志(translog)来防止数据的丢失
—— durability持久化.
translog也可以被用来提供实时CRUD
Flush 操作 类似solr hard commit
- 把所有在内存缓冲区中的文档写入到一个新的segment中
- 清空内存缓冲区
- 往磁盘里写入commit point信息
- 文件系统的page cache(segments) fsync到磁盘
- 删除旧的translog文件,因此此时内存中的segments已经写入到磁盘中,就不需要translog来保障数据安全了
每隔一定时间(es默认30分钟), 或者当translog文件达到一定大小(默认为512MB)时, 发生flush操作, 并执行一次全量提交
读者可以思考一下 fsync 操作和 flush 操作有什么不同?
为了保证不丢失数据, 就要保护translog文件的安全:
Elasticsearch 2.0之后, 每次写请求(如index、delete、update、bulk等)完成时, 都会触发fsync将translog中的segment刷到磁盘, 然后才会返回200 OK的响应;
或者: 默认每隔5s就将translog中的数据通过fsync强制刷新到磁盘.
—— 提高数据安全性的同时, 降低了一点性能.
==> 频繁地执行fsync操作, 可能会产生阻塞导致部分操作耗时较久. 如果允许部分数据丢失, 可设置异步刷新translog来提高效率.
PUT employee/_settings
{
"index.translog.durability": "async",
"index.translog.sync_interval": "5s"
}
由上述近实时性搜索的描述, 可知ES默认每秒都会产生一个新的segment文件, 而每次搜索时都要遍历所有的segment, 这非常影响搜索性能.
为解决这一问题, ES会对这些零散的segment进行merge(归并)操作, 尽量让索引中只保有少量的、体积较大的segment文件.
这个过程由独立的merge线程负责, 不会影响新segment的产生.
同时, 在merge段文件(segment)的过程中, 被标记为deleted的document也会被彻底物理删除.
gc大户 段合并
段合并操作

segment的归并是一个非常消耗系统CPU和磁盘IO资源的任务, 所以ES对归并线程提供了限速机制, 确保这个任务不会过分影响到其他任务
限速配置 indices.store.throttle.max_bytes_per_sec的默认值是20MB,固态硬盘 这个值可以是500mb或者更高, 你会感受飞一样的索引体验
相关配置:
优先归并小于此值的segment, 默认是2MB:
index.merge.policy.floor_segment
一次最多归并多少个segment, 默认是10个:
index.merge.policy.max_merge_at_once
一次直接归并多少个segment, 默认是30个
index.merge.policy.max_merge_at_once_explicit
大于此值的segment不参与归并, 默认是5GB. optimize操作不受影响
index.merge.policy.max_merged_segment
强制将segment归并为1个大的segment:
POST employee/_optimize?max_num_segments=1
此操作不受任何资源限制, 在索引频繁更新时对大索引操作将是致命的, 对于静态索引能够带来显著查询性能提升
关于段合并的一些思考
Solr 的 mergeFactor
mergeFactor粗略地确定段的数量。mergeFactor值告诉Lucene在将它们合并到单个段之前要构建多少相等大小的段。 例如,如果将mergeFactor设置为10,则将为添加到索引的每1000(或maxBufferedDocs)个文档在磁盘上创建一个新段。 当添加大小为1000的第10个分段时,所有10个分段将合并为大小为10,000的单个分段。 当添加了10个大小为10,000的这样的段时,它们将被合并成包含100,000个文档的单个段,等等。 因此,在任何时候,在每个索引大小中将不超过9个段

Es 并没有最大段数限制 而是对合并线程的资源控制
从一定程度上保证了索引吞吐量和系统稳定性,但是牺牲了一些查询性能
总结
索引是搜索引擎资源消耗最为严重的地方,从索引流程上来看, es 跟solr没有明显的区别, 唯一的区别是两边对一些主要流程细节上的控制, 而这些细节正是作为搜索开发应该学习并了解的, 他们对于索引吞吐量提升和集群稳定性至关重要.关于查询
还记得solr的查询缓存有哪些吗? 可以移步我之前的文章, 关于solr的查询缓存http://124.71.163.254/?p=130
filterCache: 过滤器缓存, 主要存储fq 查询后的结果集合
queryResultCache: 查询结果缓存,针对查询条件的完全有序的结果
documentCache:用来保存(doc_id,document)对的
Lucene FieldCache: 值到文档的有序表, 可以由docvalue cache代替
以及缓存预热 autowarm
es的查询缓存
Node Query Cache: 类似solr filterCache 但是是节点级别, 分两个级别
第一级是Query ,第二级是Segmemt
Field data Cache: 基于docvalue 构建,主要用于sort以及aggs的字段, 段级别,
类似lucene的fieldcache
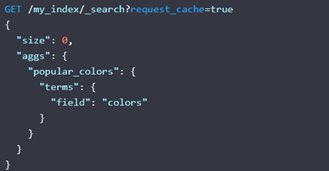
Shard Request Cache: 类似queryResultCache 查询结果缓存,主要用于缓存size=0的请求,aggs和suggestions,还有就是hits.total
ES 缓存在5.0 之后取消了预热操作, 唯一需要预热的是 linux cache

ES Node Query Cache
特点:主要用于缓存Filter中的Query结果,基于LRU策略,数据结构是Bitset, 节点级别, 节点所有索引共享, 默认为堆内存10%, 是基于段的
什么样的Query会被缓存
对于TermQuery、MatchAllDocsQuery等这种查询都不被缓存。当BooleanQuey的字节点为空时不会被缓存,当Dis Max Query的Disjuncts为空时不会被缓存。
对于历史查询次数有要求,对于消耗高昂的Query只需要2次就加入缓存,其他的默认是5次,对于BooleanQuery和DisjunctionMaxQuery次数为4次。默认的,这个历史查询的数量是256。什么样的segment会被缓存
Segment中文档数大于100000或者大于整个索引大小的3%新索引的文档,缓存会失效或者重新构建吗
缓存不会失效,而是通过判断文档是否符合Query的条件,如果符合条件的话则会将文档加入到Bitset中
跟solr的对比
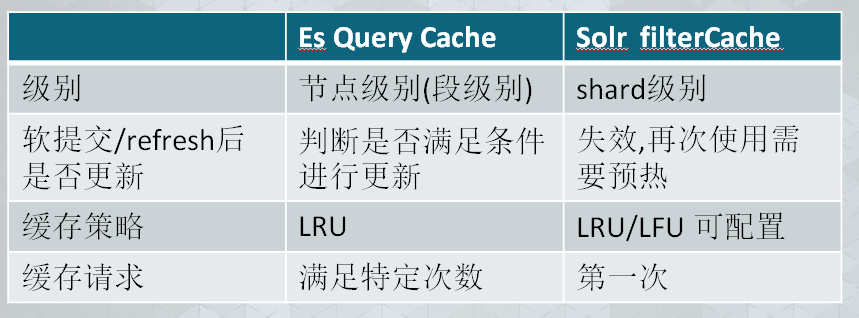
Solr 的soft commit
- tlog 不会被截断,它会继续增长。
- 新增的文档会可见。
- 某些 cache 必须重新加载(field cache)。
- 顶层的 cache 会失效。
- autowarming 会被触发。
- 新的索引段会生成。
从solr的提交过程,可以看出 solr的每次软提交都需要对cache重新生成, 而es只需要生成新提交的部分缓存
ES Field data Cache
特点:用于sort以及aggs的字段, 段级别
构造时机:
进行聚合查询时
失效时间:
- 段合并
- 超出设置上限(默认是无限)
它的构造非常消耗系统资源, 我们在kibana上进行报表统计时的长时间查询就是在
进行此cache的构造, 第一次查询往往较慢而后面就比较快的原因是走了此缓存, 需要
避免在有分词的字段上进行聚合排序
ES Shard Request Cache

默认只缓存size=0的和聚合结果, 如果要特殊指定查询走此缓存,
需要在请求时设置request_cache=true, 此缓存在refresh后失效
es对内存的使用
在一个es节点内, 内存消耗大户主要有以下几块
- segment memory
- filter cache
- field data cache
- bulk queue
- indexing buffer
- state buffer
- 超大搜索聚合结果集的fetch
- 对高cardinality字段做terms aggregation
segment memory
Segment不是file吗?segment memory又是什么?
前面提到过,一个segment是一个完备的lucene倒排索引,而倒排索引是通过词典 (Term Dictionary)到文档列表(Postings List)的映射关系,快速做查询的。 由于词典的size会很大,全部装载到heap里不现实,因此Lucene为词典做了一层前缀索引(Term Index),这个索引在Lucene4.0以后采用的数据结构是FST (Finite State Transducer)。 这种数据结构占用空间很小,Lucene打开索引的时候将其全量装载到内存中,加快磁盘上词典查询速度的同时减少随机磁盘访问次数。
segment越多,瓜分掉的heap也越多,并且这部分heap是无法被GC掉的
减少segment memory 的方法:
- 删除不用的索引
- 关闭索引 (文件仍然存在于磁盘,只是释放掉内存)。需要的时候可以重新打开。
- 定期对不再更新的索引做optimize (ES2.0以后更改为force merge api)。这Optimze的实质是对segment file强制做合并,可以节省大量的segment memory
总结
ES宗旨: 一切设计都是为了提高搜索的性能
内存的使用,包括缓存\cache 以及尽可能将文件放进系统缓存中
ES的优化策略
总结: 将磁盘里的东西尽量搬进内存,减少磁盘随机读取次数(同时也利用磁盘顺序读特性),结合各种奇技淫巧的压缩算法,用及其苛刻的态度使用内存.
后记: 此文乃抛砖引玉, 性能优化, 非一日之功, 而大道至简, 没有适用于所有业务的优化方法, 这些底层的原理正是我们进行性能探索的秘密武器, 以对性能极致追求的心, 去实战中总结吧!